Artificial intelligence keeps moving FAST, and Alibaba’s Qwen AI team just released something that would change our future: Qwen 3 Omni.
Now, unlike most LLMs (Large Language Models), this one is not just about text. It’s natively end-to-end multimodal, which means it can understand not just text, but also images, audios, and even videos… All inside one model.
In this article, I’ll walk you through what makes Qwen 3 Omni special, show some real demos, and explain whether you can actually run this model locally.
👉 Watch the full hands-on video here:

What Is Qwen 3 Omni?
Qwen 3 Omni is the newest model family from Alibaba’s Qwen AI project. It’s designed to process multiple types of input seamlessly. Instead of bolting audio and video on top of a text model (like GPT-4o or Gemini), Qwen 3 Omni was trained end-to-end across modalities.
The result: a model that feels more natural when switching between text, voice, and visual understanding.

Key Features
- State-of-the-art across modalities: Early text-first pretraining and mixed multimodal training provide native multimodal support. While achieving strong audio and audio-video results, unimodal text and image performance does not regress. Reaches SOTA on 22 of 36 audio/video benchmarks and open-source SOTA on 32 of 36; ASR, audio understanding, and voice conversation performance is comparable to Gemini 2.5 Pro.
- Multilingual: Supports 119 text languages, 19 speech input languages, and 10 speech output languages.
- Speech Input: English, Chinese, Korean, Japanese, German, Russian, Italian, French, Spanish, Portuguese, Malay, Dutch, Indonesian, Turkish, Vietnamese, Cantonese, Arabic, Tagalog, Urdu.
- Speech Output: English, Chinese, French, German, Russian, Italian, Spanish, Portuguese, Japanese, Korean, Tagalog.
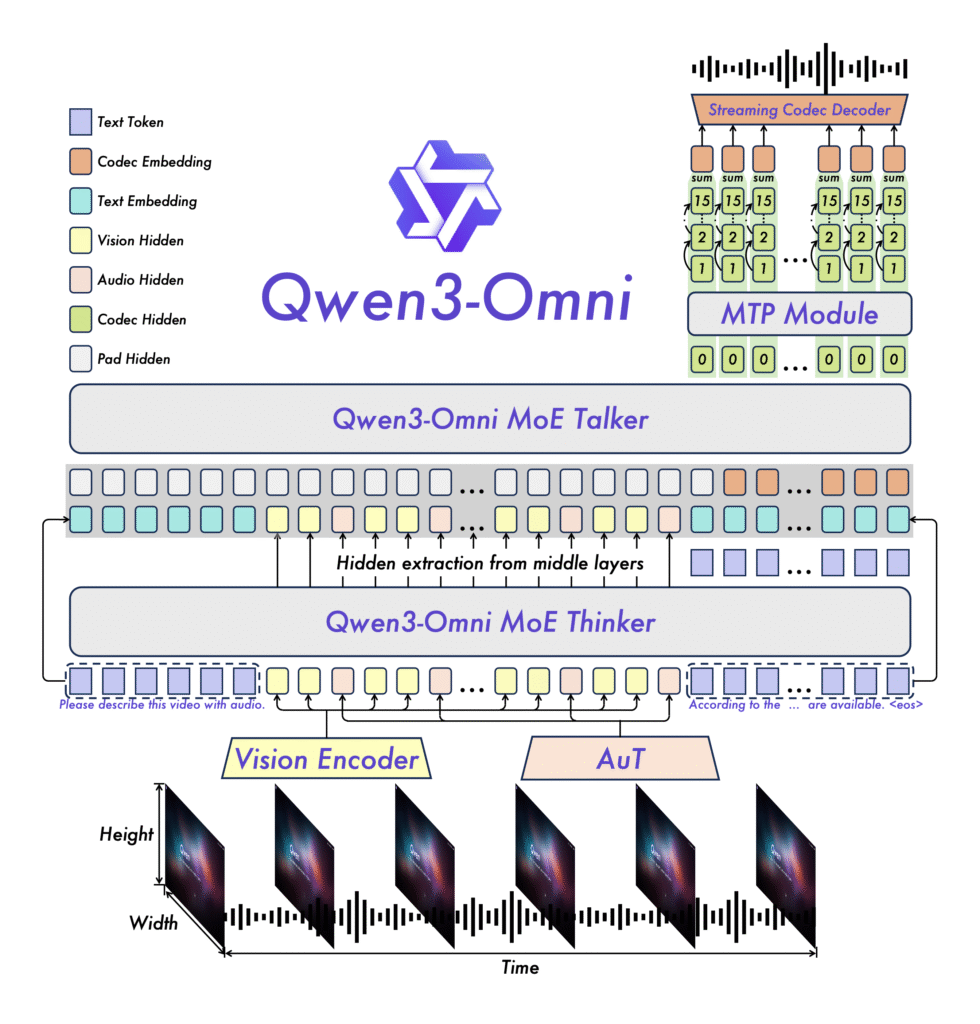
- Novel Architecture: MoE-based Thinker–Talker design with AuT pretraining for strong general representations, plus a multi-codebook design that drives latency to a minimum.
- Real-time Audio/Video Interaction: Low-latency streaming with natural turn-taking and immediate text or speech responses (200ms average).
- Flexible Control: Customize behavior via system prompts for fine-grained control and easy adaptation.
- Detailed Audio Captioner: Qwen3-Omni-30B-A3B-Captioner is now open source: a general-purpose, highly detailed, low-hallucination audio captioning model that fills a critical gap in the open-source community.
Model Architecture
The Three Versions of Qwen 3 Omni
The Omni family currently includes three specialized models:
- Captioner → Generates captions and transcriptions from audio (great for subtitles, meeting notes, or lecture summaries).
- Instruct → General-purpose instruction-following model. This version can reply in both text and audio.
- Thinking → Designed for reasoning-heavy tasks, with deeper step-by-step explanations. (Text-only output.)
In my tests, I used Qwen 3 Omni 30B (A3B Instruct), which balances performance with responsiveness.
Benchmarks: How Does It Perform?
According to the official release, Qwen 3 Omni achieved:
- State-of-the-art on 32 benchmarks
- #1 overall on 22 out of 36 audio and video tasks
That puts it ahead of heavyweights like Gemini 2.5 Pro and GPT-4o Transcribe on several evaluations.
Another standout feature: Qwen 3 Omni can process up to 30 minutes of audio input. That’s huge for real-world use cases like lectures, podcasts, or business meetings.
Live Demos: What Qwen 3 Omni Can and Can’t Do
Here are a few hands-on examples from my video:
- 🎲 Chess Helper → Qwen 3 omni could analyze a chessboard shown in a video/screenshot and it managed to suggest a move. Although, after a minute or so, it started bugging and repeated the same response no matter how much you ask it again.
- 🎸 Guitar Theory → I played some chords and sadly, its response was far off from the reality. I was honestly expecting it to also give a sound but no, it can only produce speech.
- 🎥 Video Understanding → Given a short clip, it described what was happening in the video. I tried trolling it like what I did in the video above, but it never went beyond a basic description. My theory is that this limitation is due to it being hosted online. If you run the model locally, you might be able to bypass that censorship.
On top of that, the model also has audio output with built-in voices (Ethan, Chelsie, and Aiden), making it more conversational.
Strengths and Concerns
The strengths are very clear:
- Open-source, which means developers can build on top of it.
- Flexibility from note-taking to tutoring, there are many practical use cases.
But there are concerns too:
- Students may skip the learning process and just ask AI to “watch the video for them.”
- It’s not flawless — it couldn’t solve my Rubik’s cube, and it’s not always stronger than Gemini.
Still, it’s one of the closest open alternatives that can truly rival the best.
Final Thoughts
Qwen 3 Omni isn’t just another AI model — it feels like a step closer to assistants that actually understand the world the way we do: through language, sound, and vision.
Is it perfect? No. But it’s powerful, fun, and incredibly promising.
👉 I’d love to know: what projects would you build with Qwen 3 Omni? Drop your ideas in the comments.
And if you found this useful, make sure to watch the full demo video and subscribe for more AI deep dives.